Vor gut zwei Jahren hatte ich schon einmal etwas zu meinem „Pet Project“ rund ums Münchner Ratsinformationssystem geschrieben. Leider lag das das Projekt danach für eine ganze Weile brach, insbesondere da die Klärung der rechtlichen Aspekte im Getriebe wechselnder Zuständigkeiten in der Münchner Verwaltung im Sande verlaufen ist. In den letzten Monaten habe ich aus zwei Gründen wieder mehr Elan gefunden, um das Projekt voranzutreiben: zum einen habe ich, seit ich in den Laimer Bezirksausschuss gewählt wurde, seit Mai fast täglich das „Vergnügen“, mit dem Münchner Ratsinformationssystem in Berührung zu kommen, Aggro-„Das geht doch besser!“-Reflexe inklusive. Zum anderen habe ich, ebenfalls seit Mai, über die „OK Labs“ der Open Knowledge Foundation ein gutes organisatorisches Umfeld gefunden, in dem man das Projekt aufhängen kann, um es zu mehr als nur meinem Privat-Projekt zu machen.
Der Name „OpenRIS“ ist ein reiner Arbeitstitel, ich werde den Namen dementsprechend austauschen, sobald es einen endgültigen Titel gibt.
Welche Probleme soll das Projekt lösen?
Das Ratsinformationssystem (RIS) bietet eine unglaubliche Zahl an Dokumenten rund um den Münchner Stadtrat und die Bezirksausschüsse (BAs), von Sitzungsvorlagen, Tagesordnungen und Niederschriften hin zu Stadtratsanträgen und – noch wichtiger, da meist noch informativer – den Stellungnahmen der Referate dazu. Geschätzt knapp 140.000 Dokumente. Nur: es ist furchtbar unübersichtlich und unpraktisch. Zur Einführung als neu gewählte Bezirksausschussmitglieder bekamen wir eine zehnseitige bebilderte Anleitung, wie man darin Beschlüsse finden kann – was für die Hilfsbereitschaft der Stadtverwaltung spricht, aber nicht gerade für die Usability des RIS, das ja eigentlich die Politik den BürgerInnen gegenüber transparent machen soll. Wichtige Funktionen fehlen, und eine nur schlecht funktionierende Volltextsuche rundet die Sache ab.
Kernfunktionen
OpenRIS soll einerseits die gezielte Volltextsuche nach Themen durch einen zentralen Suchindex erleichtern, der sich unabhängig vom Dokumenttyp mit der von Suchmaschinen her bekannten Syntax durchsuchen lässt – auch bei Dokumenten, die nur in gescannter Form vorliegen (OCR).
Vor allem aber soll es OpenRIS interessierten BürgerInnen leichter machen, auf dem Laufenden zu bleiben – zu konkreten Sachthemen sowie zu allen Angelegenheiten, die sich um ihr Wohngebiet (z.B. ihren Stadtteil) drehen. Dafür gibt eine Timeline-Ansicht aller Dokumente, die sich entweder auf die Stadt allgemein oder auf einen konkreten Stadtteil beziehen. Gefundene Dokumente werden anhand enthaltener räumlicher Bezugspunkte auf einer Karte eingezeichnet. Zentral ist dabei eine Benachrichtigungsfunktion: es ist möglich, zu einer Suche (sowohl im Volltext als auch zu Metadaten wie Stadtteilbezug) eine Benachrichtigung per E-Mail einzurichten, sodass man informiert wird, sobald es neue Dokumente gibt, die diesen Kriterien entsprechen.
OpenRIS wird aber nicht (wie z.B. Offenes-koeln.de) die Dokumente selbst anbieten – sondern stattdessen schlicht auf die Dokumente im Original-RIS verlinken.
Welche Probleme kann das Projekt nicht lösen?
OpenRIS kann keine Dokumente auffindbar machen, die nicht ohnehin schon im (öffentlichen) Ratsinformationssystem zu finden sind. Es kann also nichts daran ändern, wenn Dokumente gar nicht oder nur mit größerer Verzögerung online gestellt werden. Letzteres scheint leider gerade im Umfeld von Bezirksausschüssen sehr häufig vorzukommen.
Komponenten
OpenRIS besteht aus mehreren Teilen, die konzeptionell voneinander unabhängig sind und teils auch nicht alle zu Beginn eingebaut sein werden.
Scraping
Da das offizielle Ratsinformationssystem keine API anbietet, über welche die Metadaten abrufbar sind, ist der erste Schritt ein Scraping-Mechanismus, der die öffentlich zugänglichen HTML-Seiten des Ratsinformationssystems in eine normalisierte SQL-Datenbank umwandelt. Jede Menge Regular Expressions kommen hier zum Einsatz, die in folgendes Datenmodell bespielen:
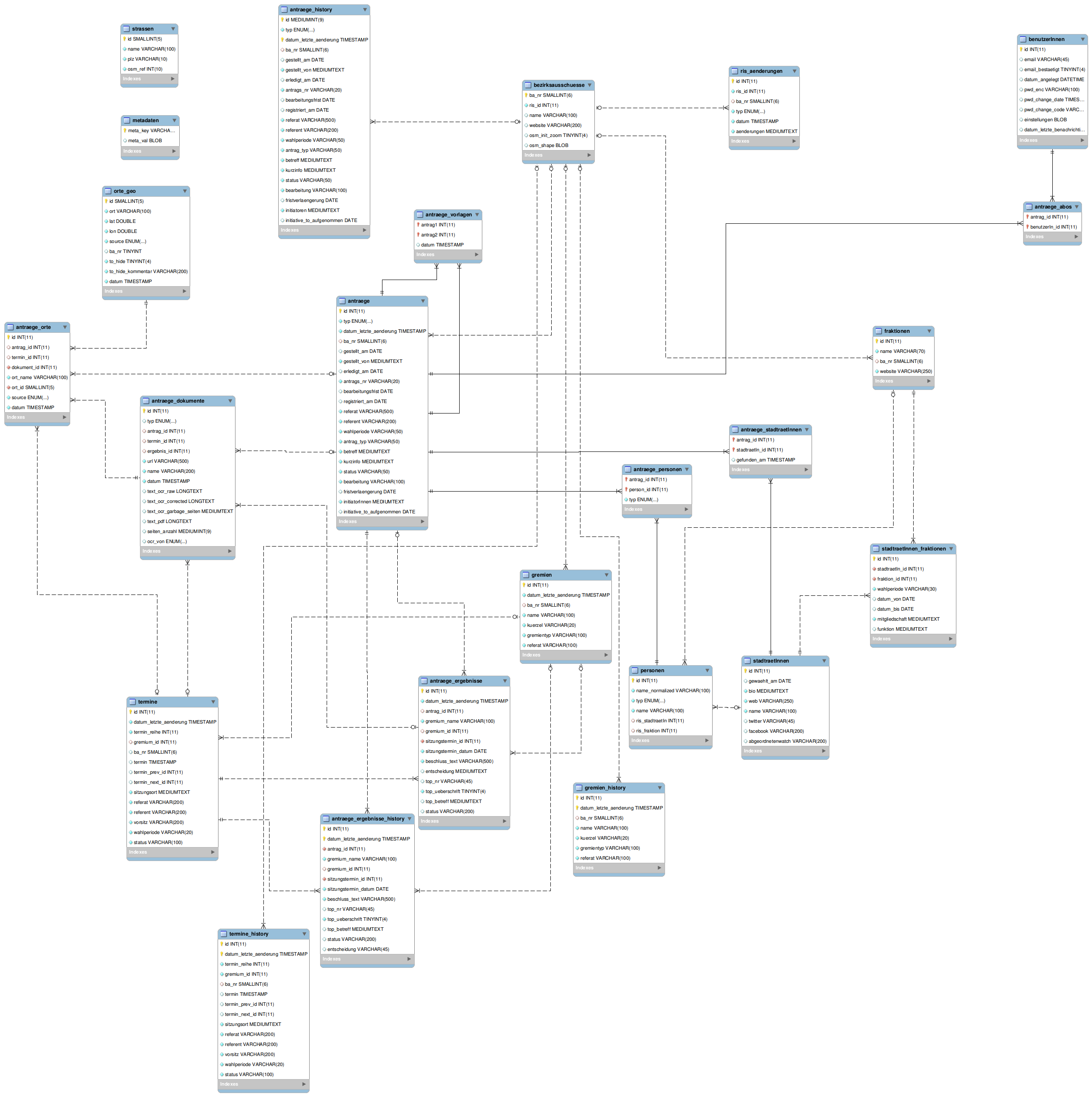
Beim aktuellen Entwicklungsstand werden die Metadaten der Stadtratsanträge, Stadtratsvorlagen, Stadtrats(ausschuss)sitzungen, BA-Anträge, BA-Initiativen, BA-Sitzungen, Bürgerversammlungsempfehlungen, und die Liste der Stadtrats- und BA-Mitglieder erfasst, sowie die Beziehungen untereinander. Bei den Versammlungen werden insbesondere auch die Tagesordnungspunkte strukturiert erfasst und die gefassten Beschlüsse indiziert. Ich versuche dabei auch, einige der technischen Probleme des offiziellen RIS zu umschiffen – beispielsweise die Encoding-Probleme (langgezogene Bindestriche sowie deutsche Anführungszeichen im Titel werden grundsätzlich als Fragezeichen dargestellt; mein Nachname entwickelt eine ganz eigene Ästhetik).
Noch nicht erfasst werden u.a. Mitgliedschaften von Personen in einzelnen Gremien, die Metadaten zu den einzelnen ReferentInnen, und vereinzeln Angaben wie beispielsweise Positionen / Funktionen von Stadtratsmitgliedern.
Das Scraping bezieht sich dabei nur auf die Metadaten, also beispielsweise, wer wann einen Antrag gestellt hat sowie den Titel des Antrags – nicht aber den tatsächlichen Text des Antrags. Während die Metadaten am Ende auch über OpenRIS abrufbar sein sollen (z.B. auch über eine API), wird das bei den vollen Texten der Anträge und Vorlagen nicht der Fall sein, da das im Gegensatz zu den Metadaten möglicherweise Urheberrechte berühren könnte.
Volltextindex & Suche
Ähnlich wie bei gängigen Web-Suchmachinen wird ein Volltextindex aller gefundener Dokumente aufgebaut, in dem nach Schlüsselwörtern und Metadaten gesucht werden kann. Als Software kommt hier Apache Solr zum Einsatz. Wird ein Dokument über die Volltextsuche gefunden, wird ein Snippet angezeigt, nicht aber der gesamte Text des Dokuments – statt dessen wird einfach die Originaldatei verlinkt, was im Münchner RIS (anders als z.B. beim Kölner) ohne Probleme möglich ist.
Der Text wird auf zwei Wegen aus den Dokumenten ausgelesen: bei regulären PDF-Dateien, in denen der Text auch als solcher gespeichert wird, wird der Text mittels Apache PDFBox extrahiert (was bei meinen Tests zuverlässiger funktionierte als das verbreitetere pdf2text). Da sich unter den Dokumenten aber auch viele TIFF-Dateien und PDFs mit nur gescannten Bildern befinden, wird grundsätzlich jedes Dokument zusätzlich noch durch zwei OCR-Programme verarbeitet: zunächst das freie Tesseract, das passable Ergebnisse liefert und sich als Kommandozeilentool leicht automatisch einbinden lässt. In einem zweiten Schritt dann noch durch das kostenpflichtige OmniPage Ultimate, das in meinen Tests sehr viel bessere Ergebnisse lieferte als Tesseract, sich als reines Windows-Programm aber nur sehr eingeschränkt automatisieren lässt (zumindest in der noch bezahlbaren Version).
Aus dem Volltext der Dokumente wird dann noch versucht, Ortsbezüge herzustellen, indem im Text nach bekannten Straßennamen gesucht wird, ggf. mit den folgenden Hausnummern, und diese Angaben dann durch eine der vielen gängigen Geocoding-Webservices in Geodaten umgewandelt werden. Das funktioniert zurzeit nur so semi-toll; zwar gut genug, dass es einen wirklichen Mehrwert bietet – aber leider noch mit vielen fehlerhaften Treffern. Sei es weil eine Straße in einer anderen Stadt mit dem selben Namen wie eine Münchner Straße erwähnt wird, sei es, dass die „str.“-Abkürzung nicht immer für „Straße“ steht, sondern gerne auch mal für „Stadtrat“ und dadurch Missverständnisse entstehen. Das Problem haben auch vergleichbare Projekte anderer Städte wie beispielsweise „Offenes Köln“, sodass die Optimierung dieses Algorithmus ein lohnenswertes, für sich alleine stehendes Projekt sein könnte.
Diese Komponente ist inzwischen funktional weit gehend benutzbar (um das Wort „fertig“ vermeiden, das bei Web-Projekten bekanntermaßen nie zutrifft).
Web-Interface
Ein Großteil der Arbeit fließt momentan in das Web-Interface, über das neue Dokumente angezeigt und auf einer interaktiven Karte verzeichnet werden, Informationen zur Zusammensetzung des Stadtrats und der Bezirksausschüsse, eine Volltextsuche, usw. Technisch ist daran wenig Spannendes.
Ich erwähne dabei nur mal, dass ich vom einbettbaren Kartenmaterial von Skobbler sehr angetan bin, insbesondere da es auf den Daten von Openstreetmap basiert, die meinem Empfinden nach sehr viel detaillierter als Google Maps & co sind, in der fertig gerenderten Fassung aber meist große „ästhetische Defizite“ aufweist. Von der Kombination Leaflet.js + Skobbler bin ich sehr angetan, insbesondere seit letzteres auch Retina-kompatible Grafiken ausliefert.
Die spannendste Funktion des Web-Interface wird sicher die Möglichkeit sein, sich E-Mail-Benachrichtigungen einrichten zu können. Das funktioniert so, dass jede Suchanfrage (z.B. eine Kombination aus Stadtteilbezug und einem Suchbegriff, oder dem initiierenden Stadtratsmitglied) gespeichert und einer E-Mail-Adresse zugeordnet werden kann. Immer wenn ab dann dem Volltextindex neue Dokumente hinzugefügt werden, wird überprüft, ob es gespeicherte Suchanfragen gibt, die auf das neue Dokument zutreffen – und der Inhaber wird benachrichtigt. Darüber hinaus soll es auch möglich sein, einzelne Anträge zu abonnieren, um dann entweder über neue Dokumente zu diesem Antrag benachrichtigt zu werden (z.B. wenn ein Referat eine Anfrage beantwortet), oder über Statusänderungen (z.B. wenn der Antrag einer konkreten Sitzung zugeordnet wird).
E-Mail ist dabei die naheliegendste Benachrichtigungsform – andere Formen wie beispielsweise GCM oder APS für Android/iOS-Apps wären aber für die Zukunft auch denkbar.
Alternativ zu den Benachrichtigungen soll es die Suchergebnisse zu bestimmten Suchanfragen auch in Form von RSS-Feeds geben.
Das Web-Interface ist zurzeit aber noch sehr Alpha, und da sich hier einerseits noch Leute vom „OK Lab“ einbringen wollen, und ich das andererseits auch mindestens noch einer Person, die von Design mehr versteht als ich vorlegen will, dürfte da noch sehr viel passieren.
OParl-API
Seit einigen Monaten gibt es die OParl-Initiative, die einen offenen Standard zum Abruf von Daten aus parlamentarischen Informationssystemen erstellt – der erste Entwurf, wurde im Mai 2014 veröffentlicht. Über OParl wäre es beispielsweise möglich, mobile Apps zu entwickeln, welche auf die Daten verschiedener Ratsinformationssysteme zugreifen kann. Der Standard beschränkt sich momentan recht stark auf die Modellierung des Datenmodells und bietet einige wenige Anfragetypen an.
Meiner ersten Einschätzung nach ist das OParl flexibel genug, um die Datenstruktur des Münchner RIS abzubilden (insb. auch die recht spezielle Konstellation mit Stadtrat und Bezirksausschüssen). Daher bietet es sich an, diese API auch in OpenRIS zu implementieren. Diese API würde ausschließlich auf die Metadaten aufsetzen, die durch das Scraping gewonnen werden, da eine Volltextsuche derzeit vom OParl-Standard noch nicht vorgesehen zu sein scheint, und der Volltextabruf über OpenRIS aus den oben genannten Gründen voraussichtlich nicht möglich sein wird.
Für viele praktische Anwendungsfälle, wie die genannte Volltextsuche, eine Suche nach Ortsbezug, oder eine Benachrichtigungsfunktionalität, wird es aber „proprietäre“ Erweiterungen der API benötigen, bis sich diese vielleicht in einer zukünftigen Version von OParl wiederfinden.
BürgerInnenbeteiligung
Bei den OK Labs (und auch den inoffiziellen Vorgängern, den MOGDy-Treffen) kamen eine ganze Reihe an Ideen, die Plattform um interaktive, bis hin zu partizipativen Komponenten zu ergänzen. Ein Vorbild dafür ist „Frankfurt Gestalten“, über das BürgerInnen eigene Initiativen online stellen können. Ein Knackpunkt für solche Plattformen ist aber die Rückkopplung in die Stadtverwaltung bzw. -politik hinein: in einem Blog-Posting vom Mai ’14 beklagen die Betreiber von Frankfurt Gestalten auch genau diesen fehlenden Rückkanal als großen Nachteil ihrer Plattform. Wenn OpenRIS um eine solche Komponente ergänzt werden soll, wird daher sehr viel Arbeit in die Ausarbeitung eines Konzepts fließen müssen, damit am Ende keine Plattform entsteht, die BürgerInnenbeteiligung nur vorgaukelt – und sich auch von den bestehenden Angeboten (wie beispielsweise das bis vor kurzem laufende „Direkt zu Ude“, oder den Gefahrenatlas der Süddeutschen) abzuheben.
Vergleichsweise einfach wären dagegen Ideen, wie sie Georg Kronawitter in einem Stadtratsantrag vor einigen Jahren schon formulierte.
Statistische Daten
Eine weitere Möglichkeit, OpenRIS weiter auszubauen, wäre, statistische Daten mit zu integrieren, um eine gemeinsame Plattform zu haben, um solche Stadtbezogene Informationen anzubieten. Relevant dürften dabei insbesondere die Zahlen des Statistischen Amts München sein.
Entwicklung
Angaben dazu, wann das Projekt live geht, mache ich besser nicht mehr – mit „kommt jetzt wirklich bald“ habe ich mich schon vor zwei Jahren in die Nesseln gesetzt.
Den Quelltext des aktuellen Entwicklungsstands gibt es aber schon auf Github, und das Projekt wird natürlich auch unter eine OpenSource-Lizenz gestellt.